


Rédigé par:
Chanel Robin
Étudiante à la maîtrise, Université de Montréal
Partie 1 : Historique de l’Internet : comprendre les raisons d’être des alternatives.
Internet rime désormais avec le nom des géants du numérique – les dénommés « GAFAM » – Google, Amazon, Facebook (Meta), Apple et Microsoft (et bien d’autres!). Ces noms de marque sont aussi synonymes de surveillance, d’invasion de la vie privée, de capitalisation de nos données, et ce, au vu et au su de tou.te.s. Au Lab-Delta, nous avons à cœur les technologies alternatives à celles proposées par les compagnies ci-dessus. C’est pourquoi, dans cette série de trois articles, nous vous proposons quelques pistes et réflexions pour guider votre processus de découverte du numérique « alternatif », un monde mené par les mouvements du logiciel libre et du « open source ». Il sera d’abord question de 1) l’histoire du numérique pour comprendre la nécessité des médias sociaux alternatifs. Ensuite, nous présenterons le fonctionnement d’une forme d’alternative, 2) les réseaux sociaux décentralisés du Fediverse. Enfin, nous parlerons plus en profondeur de 3) la couche logicielle « libre » qui supporte ces alternatives, et ce que cette liberté implique.
En guise d’introduction aux technologies numériques alternatives, il nous faut retourner en arrière dans l’histoire de l’Internet et du World Wide Web. Dans ce premier article d’une série de trois, nous verrons que, depuis ses débuts, l’Internet a changé, et pas toujours de la « bonne » manière.
À ses débuts, l’Internet avait pour but d’être décentralisé. Il puise ses origines dans le premier réseau d’ordinateurs et de machines qui coordonnait les activités de la Défense américaine et des communautés scientifiques des États-Unis durant la guerre froide, l’ARPANET (Loveluck, 2015). L’ancêtre d’Internet était conçu de manière décentralisée, dans un réseau dit « distribué » (Baran, 1968, cité dans Loveluck, 2015, p.55). L’avantage de ne pas comporter de nœud central est que ce type de réseau était prévu pour mieux résister advenant une attaque nucléaire : si l’une des parties se faisait détruire, le réseau dans son ensemble n’aurait pas été affecté (Loveluck, 2015, p.55). Après cette période de tension entre Russes et Américains, le successeur d’ARPANET (Internet) a conservé son architecture décentralisée. Ce que nous appelons Internet est le réseau d’ordinateurs capables de communiquer entre eux par le biais du protocole de communication informatique éponyme, Internet protocol (IP). Le protocole « IP » est une série d’instructions qui permet cette communication entre différentes machines.
Figure 1: Représentations visuelles des réseaux centralisés, décentralisés et distribués
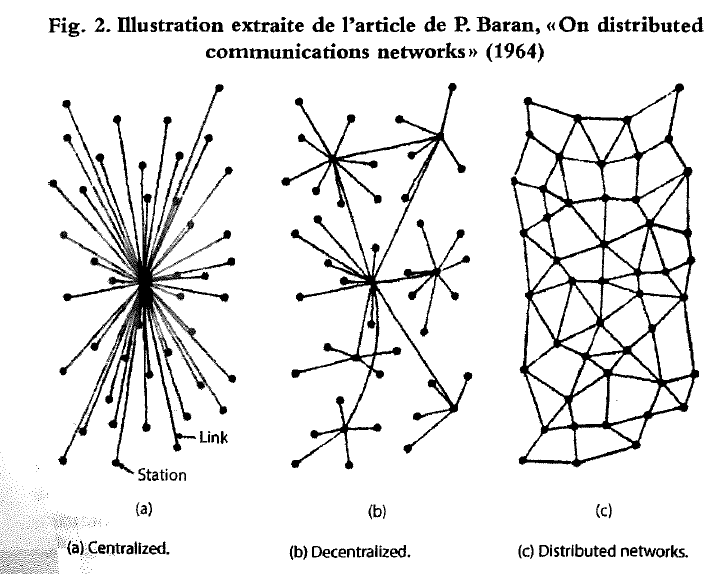
Avec l’adoption de ce protocole comme standard dès les années 1980 (Loveluck, 2015, p.59), les premières communautés en ligne voient le jour; les innovations se succèdent et font rapetisser la taille des ordinateurs, si bien que l’utilisation des ordinateurs se poursuit en dehors des laboratoires scientifiques et entre dans les demeures (ce que l’on appelle l’ère de la micro-informatique personnelle).
Le Web de Tim Berners-Lee
Dès 1989, Tim Berners-Lee a mis au point le World Wide Web. Communément appelé le « Web » et souvent confondu avec Internet, il s’agit du système hypertexte accessible aux navigateurs web (tels que Firefox, Safari ou Chrome). On retrouve dans cette application d’Internet le souci de connexion entre les ordinateurs selon un principe de non-centralisation (Berners-Lee, 1989). Pour lui, l’information devait d’abord être facilement trouvable, cataloguable et partageable (Berners-Lee, 1989, notre traduction), ce qui fait du World Wide Web un hypermédia qui met en relation des documents textuels, des graphiques, des images, des vidéos (Bardini et Proulx, 2000). Partant de ce principe d’écriture non-linéaire basée sur l’association d’idées (par ex. : les menus, la barre de navigation, le système de fichiers « Finder »), le Web tel que l’on connait est construit « sur des principes d’ouverture, de décentralisation et de distribution » (Cabello et al., 2013, p.44, notre traduction).
Quelque trente ans plus tard, le Web de Berners-Lee a radicalement changé de forme. Voyant la montée des GAFAM, Berners-Lee partageait récemment ses craintes d’une recentralisation du contenu du Web par ces grandes compagnies : « chaque site est un silo, séparé des autres par [une sorte de] mur » (Berners-Lee, 2010, notre traduction). Selon lui, ces compagnies constituent un frein à la poursuite de la décentralisation des infrastructures numériques, principe qui fait partie du développement de l’Internet et du Web depuis les débuts.
« Les plus jeunes de ce monde ne savent probablement pas comment le Web était, avant » (Dash, 2012, notre traduction).
Le cas des réseaux sociaux numériques
Pour la majorité d’entre nous, utilisateur.trice.s moyen.ne.s dont les données personnelles n’apparaissent pas d’emblée susceptibles d’être dignes d’intérêt, des plateformes web comme Facebook sont si pratiques pour accéder rapidement à ce qui se passe autour de chez nous et dans le monde. Et que dire de Google Maps? Un navigateur GPS qui guide notre route dans tous les coins du monde. Leur point en commun : ce sont toutes des technologies dites conviviales (user-friendly). Au départ, le théoricien du concept de convivialité, Ivan Illich, considérait qu’une technologie conviviale en est une qui « […] n’accapare pas ses utilisateur.trice.s », c’est-à-dire qu’elle leur sert sans qu’iels en ait constamment besoin (Mitcham, 2009, p.305, notre traduction).
Le Web étant désormais mené par ces compagnies, il se « réduit » à être le lieu du capitalisme (FSF, 2012, notre traduction), notamment à cause des mécanismes mis en place pour assurer une publicité de plus en plus précise grâce aux traces de navigation laissées par les utilisateur.trice.s. Ces plateformes, tout comme les appareils qui les supportent, réussissent à accaparer notre attention et à la concentrer sur ces plateformes. Bien que leur portée mondiale ait étendu l’accès à Internet pour tou.te.s, cette centralisation orchestrée par les géants du Web devrait pourtant nous amener à reprendre en main nos habitudes numériques. Force est de constater que notre utilisation de l’Internet et de ses applications est rendue bien loin du « simple » principe de l’hypertexte et de communication d’information de manière décentralisée; nous en dépendons. C’est là que le charme de Google, d’Instagram, de TikTok opère : leurs formats clé-en-main les font paraitre comme fonctionnant « par magie » (Bardini et Proulx, 2000, p.6). En effet – et c’est là le problème – la plupart d’entre nous ne savent pas comment les technologies numériques que nous utilisons quotidiennement fonctionnent.
Heureusement, des solutions existent; elles feront par ailleurs l’objet des prochains articles. Nous traiterons prochainement des réseaux sociaux numériques alternatifs à Facebook, Instagram, Twitter et YouTube tels que diaspora*, PixelFed, Mastodon, et PeerTube . Ceux-ci reprennent les principes d’ouverture et de décentralisation de manière à donner aux utilisateur.trice.s l’accès direct à l’infrastructure qui se cache sous l’interface visuelle (Gehl, 2015). Il va sans dire que l’utilisation de ces plateformes décentralisées nécessite un apprentissage de quelques rudiments d’informatique : on ne s’inscrit jamais au réseau social en entier, mais à une « instance » (comme une « île » dans un archipel) de celui-ci. Cependant, c’est grâce à ces connaissances que l’on peut véritablement reprendre le contrôle sur notre vie numérique!
Avec cette courte introduction, nous espérons vous avoir piqué votre curiosité et vous intéresser à ce qui se passe « sous le capot » de votre ordinateur portable, de votre téléphone intelligent, et même des applications et plateformes web. En terminant la partie historique, je laisse les mots de Tim Berners-Lee vous habiter en attendant la prochaine section sur les réseaux sociaux numériques alternatifs :
Why should you care? Because the Web is yours. It is a public resource on which you, your business, your community and your government depend. […]
We create the Web, by designing computer protocols and software; this process is completely under our control. We choose what properties we want it to have and not have. It is by no means finished (and it’s certainly not dead) (Berners-Lee, 2010).
Références Partie 1 :
Bardini, T. et Proulx, S. Bardini, T., & Proulx, S. (2000). Présentation. Sociologie et sociétés, 32(2), 3-8. https://doi.org/10.7202/001019ar
Berners-Lee, T. (1989). Information Management: A Proposal. W3C. https://www.w3.org/History/1989/proposal.html
Berners-Lee, T. (2010). Long Live the Web: A Call for Continued Open Standards and Neutrality. Scientific American. https://www.scientificamerican.com/article/long-live-the-web/
Cabello, F., Franco, M. G. et Haché, A (2013). The Social Web beyond “Walled Gardens” : Interoperability, Federation and the Case of Lorea/n-1. Psychonology journal, 11(1). 43 – 65. https://www.academia.edu/3740280/The_Social_Web_beyond_Walled_Gardens_Interoperability_Federation_and_the_Case_of_Lorea_n_1
Dash, A. (2012, 13 décembre). The Web We Lost. https://anildash.com/2012/12/13/the_web_we_lost/
Free Software Foundation (2012). The GNU consensus Manifesto. GNU. https://www.gnu.org/consensus/manifesto.html
Gehl, R. W. (2015). The Case for Alternative Social Media. Social Media + Society, 1(2), https://doi.org/10.1177/2056305115604338
Loveluck, B. (2015). Réseaux, libertés et contrôle : une généalogie politique d’Internet. Paris: Armand Colin. 45-65.
Mitcham, C. (2009). Convivial software : An end-user perspective on free and open source software. Ethics and Information Technology, 11(4), 299-310. https://doi.org/10.1007/s10676-009-9209-7
