


Par : Marie Pier Hupé-Mongeon, Pierre Yves Maurie et Sophie Toupin
Les trois autrices et auteurs de cette réflexion de recherche ont travaillé à parts égales. Nous aimerions remercier les personnes étudiantes du cours COM-7033 Approches critiques et culturelles en communication à l’Université Laval (automne 2023), qui ont nourri nos réflexions.
Introduction
Lors de la rentrée universitaire 2023, ChatGPT était sur toutes les lèvres. Cette agent conversationnel propulsé par l’intelligence artificiel génératrice qui a été lancé par la compagnie Open AI en novembre 2022. Les membres de la communauté universitaire se questionnaient. Doit-on interdire ChatGPT et autres outils d’intelligence artificielle générative (IAG) ? Ou doit-on plutôt s’adapter et permettre leur utilisation sous conditions de référencement et de citation ? Dans le cadre du séminaire de 2e cycle Com-7033 portant sur les approches critiques et culturelles de la communication réalisé à l’automne 2023, nous nous sommes penchés, étudiants et étudiantes du séminaire, sur ChatGPT comme objet de recherche. Cette brève réflexion de recherche s’articule autour de la question suivante :
Quelles sont les implications éthiques, sociales et environnementales de ChatGPT ?
Description de la démarche
Dans cette première section, nous évoquerons le corpus de données utilisés, la méthode utilisée et sa pertinence, le nombre de collaborateurs et collaboratrices dans le séminaire et l’importance d’ouvrir le dialogue et la réflexion pour comprendre les implications de l’intelligence artificielle générative.
Le corpus de données
Tout d’abord, pour mieux comprendre ChatGPT, nous avons récolté et lu une vingtaine d’articles de journaux et de revues spécialisées portant spécifiquement sur l’agent conversationnel. Ces articles étaient publiés en anglais et en français dans des médias numériques tels que La Presse, le New York Times, le Washington Post, le Time Magazine, L’Humanité, La Croix, le Rest of World et le Rolling Stone Magazine. Nous avons également lu quelques articles scientifiques ainsi que le livre le Contre-atlas de
l’intelligence artificielle de Kate Crawford. Ces lectures nous ont permis de mieux saisir les implications de cet outil informatique.
Une démarche cartographique
Par la suite, nous avons utilisé la méthodologie de l’analyse d’une situation d’Adèle Clarke (Situational Analysis en anglais) afin de réaliser une cartographie des éléments qui composent ChatGPT (Clarke, 2003 ; Clarke et al., 2018). Cette méthodologie propose notamment la construction de « cartes » en version chaotique et/ou ordonnée qui rendent compte des éléments d’une situation tels les acteurs-actrices humains et non-humains. En dessinant des cartes à partir de notre corpus de données, cette méthodologie de recherche nous a donné des clés pour comprendre les implications trop souvent invisibles de ChatGPT. C’est grâce à cette méthodologie que nous avons été en mesure de répondre à notre question de recherche et ainsi identifier les silences quant aux implications éthiques, sociales et environnementales de notre objet de recherche.
Sur la table à dessin
Notre groupe, soit les neuf personnes étudiantes participant au séminaire, s’est divisé en trois équipes de trois. Munis de grand carton, post-it et crayons, nous avons commencé à concevoir nos cartes respectives. Au total, trois cartes en version plus ou moins chaotique ont été conçues. Celles-ci permettent de représenter ChatGPT selon une certaine complexité et d’affiner notre réflexion dans cette note de recherche (voir carte 1, 2 et 3 ci-dessous). C’est en regroupant le fruit de ce travail que nous avons ratissé un objet de recherche complexe et tenter d’identifier certains biais et angles morts pour alimenter la réflexion sur les implications éthiques, sociales et environnementales.
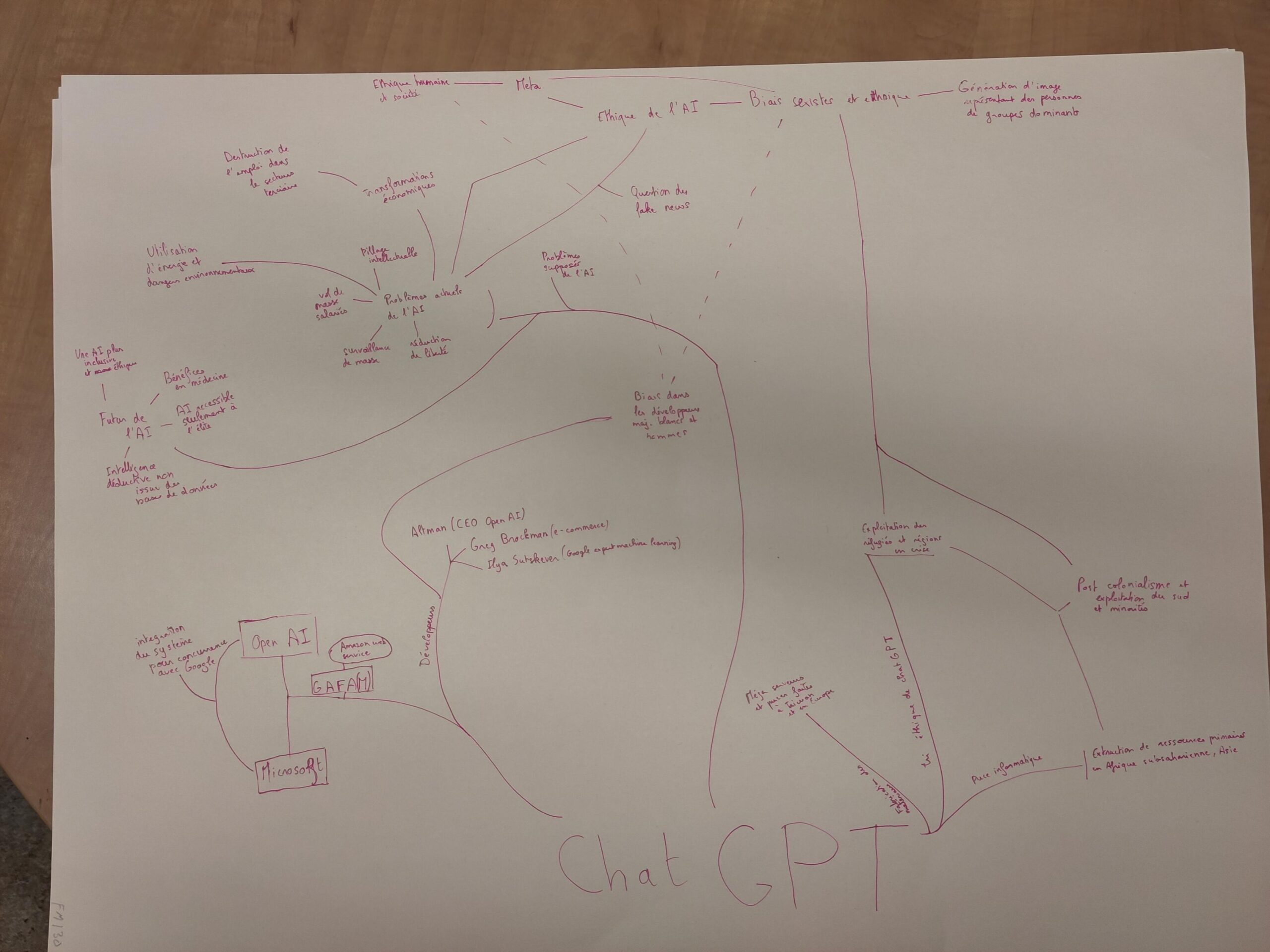
Carte de l’équipe n° 1, composée de Pierre-Yves et Yonn Etienne Jean Théodor Calvez –
ChatGPT y est schématisé en arbre. Quelles sont ses racines, ses branches pourries ou inaccessibles, ses branches porteuses de vie et d’espoir ? Des déséquilibres apparaissent, l’arbre penche dangereusement, restera-t-il debout ?
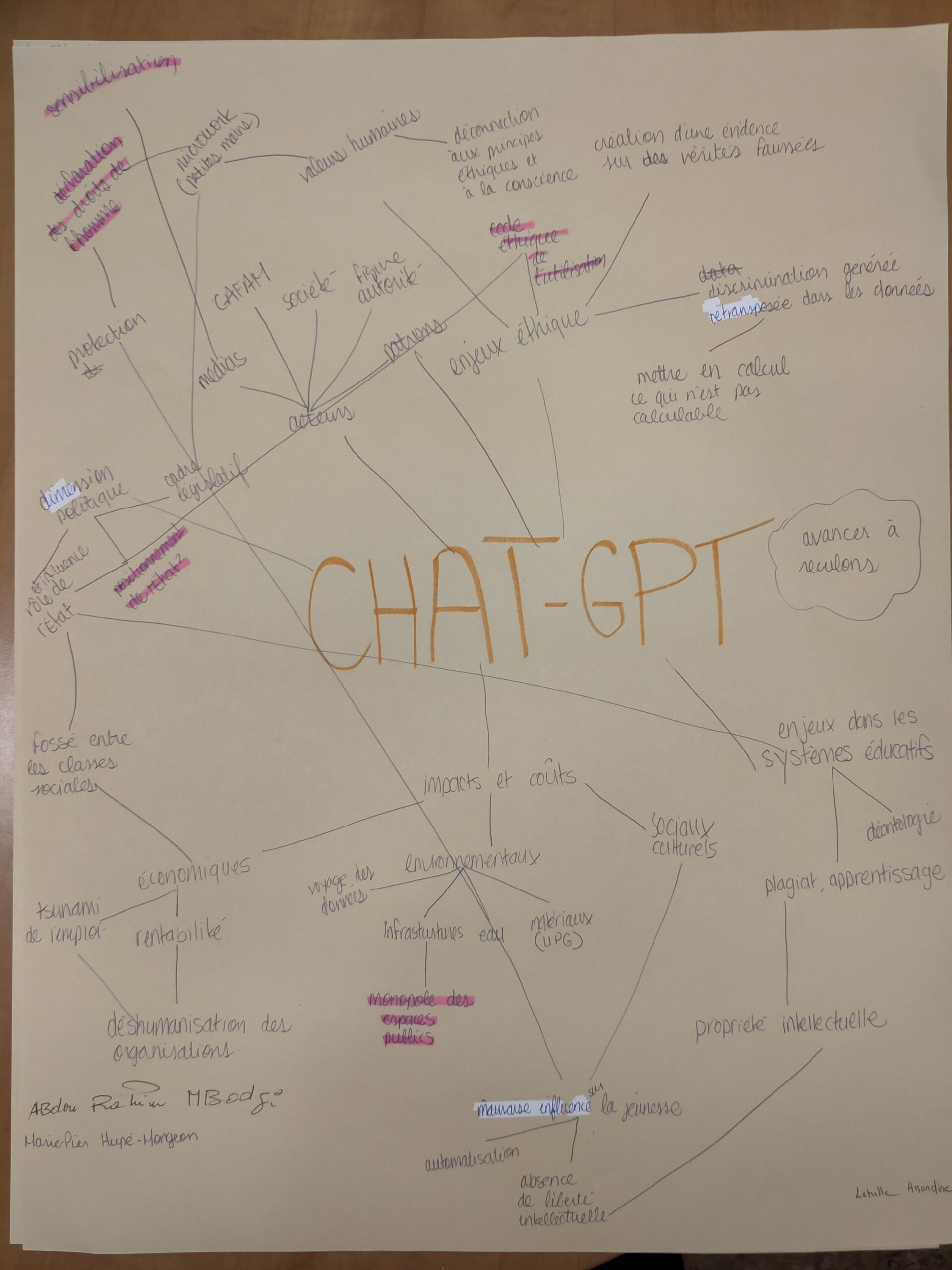
Carte de l’équipe n° 2, composée de Marie Pier Hupé-Mongeon,
Amandine Letulle et Mathilde Anne Corinne Rigaud
ChatGPT y est représenté comme une multitude de branches toutes reliées les unes aux autres par des nœuds

Carte de l’équipe n ° 3, composée de Fatima-Ezzahra Khalid, Loubna Kahia-Aoul et Perla Eboa Ebolo
ChatGPT y est conceptualisé sous la forme d’une carte mentale afin d’explorer différentes facettes de l’agent conversationnel telles que le rôle de l’humain, les dangers, l’économie, l’éthique et le futur.
Mise en dialogue critique des réflexions
Analyser l’IAG : l’importance d’une perspective critique
Dans les médias en général, les discours sur l’intelligence artificielle (IA) sont souvent empreints d’un dualisme réducteur. L’IA est trop souvent présentée soit comme un bienfait pour l’humanité (développement économique, automatisation de tâches pénibles, efficacité, etc.) soit comme l’un des pires dangers qui nous guettent (perte d’habilité cognitive, plagiat, destruction de l’humanité, etc.). Nous avons identifié ce dualisme dans certains des articles de journaux qui composent notre corpus de données. Cependant, il est important de mentionner que les articles de journalisme d’investigation que nous avons lus ainsi que ceux rédigés par des chercheur.e.s. pour le grand public nous ont permis d’approfondir notre réflexion et d’identifier les implications éthiques, sociales et environnementales de ChatGPT.
C’est le livre de Kate Crawford qui nous a permis de donner du sens à l’ensemble des éléments de notre corpus de données. En effet, dans son livre intitulé Contre-atlas de l’intelligence artificielle : les coûts politiques, sociaux et environnementaux de l’IA, Kate Crawford affirme que l’IA « n’est ni artificielle ni intelligente. Plutôt elle est à la fois incarnée et matérielle, faite de ressources naturelles, de carburant, de main-d’œuvre humaine, d’infrastructures, de logistique, d’histoires et de classification » (Crawford, 2023, p. 19). C’est en s’inspirant de cette définition au spectre large plutôt qu’en optant pour une définition technique de ce qu’est l’apprentissage machine (machine learning ou deep learning) ou d’une définition plus historique inspirée des balbutiements de la conceptualisation de l’intelligence artificielle générative (McCarthy et al., 1955) que nous abordons de front ce sujet. Comme Crawford nous le rappelle, l’IA est plusieurs choses à la fois. « C’est une idée, une infrastructure, une industrie, une forme d’exercice de pouvoir et une façon de voir » (Crawford, 2023, p. 31). Les systèmes d’IA sont tout sauf abstraits et désincarnés : ce sont des infrastructures physiques qui transforment la façon dont on voit et comprend le monde (Crawford, 2023).
En explorant les forces économiques, politiques, culturelles et historiques qui façonnent l’IA on en vient à comprendre que celle-ci n’est pas un domaine purement technique. En effet, l’industrie technologique est confrontée à des pressions de réglementation européenne, canadienne et américaine et elle domine la production de connaissances sur l’IA. Ainsi, elle a intensifié ses efforts pour créer un récit technologique positif pour faire taire et mettre de côté les critiques (Whittaker, 2021). Sans perspectives critiques, « cela menace de priver les communautés de première ligne, les décideurs politiques et le public de connaissances vitales sur les coûts et les conséquences de l’IA » (Whittaker, 2021, p.51, notre traduction). Nous pourrions également ajouter à cette liste les membres de la communauté étudiante, du corps professoral et de l’administration au sein des instances universitaires.
Ci-dessous, nous décrivons sommairement six aspects qui nous ont particulièrement interpellés au cours de notre réflexion et qui nous aident à répondre à notre question de recherche.
Aux manettes de l’IAG : l’entreprise à but lucratif Open AI
Tout d’abord, qui est derrière ChatGPT ? Les articles de fond de la presse américaine, notamment le Washington Post et le New York Times nous ont permis d’en apprendre davantage sur qui est Open AI. Lancée en 2015 en tant qu’organisme à but non lucratif, l’organisation américaine Open AI est passée, en 2019, à un modèle à but lucratif afin d’attirer des investisseurs. D’ailleurs, la multinationale informatique Microsoft a depuis investi plus de 11 milliards dans l’outil et il en coûte 700 000 USD par jour pour le faire fonctionner (O’Brien & Fingerhut, 2023). Cette stratégie de faire fonctionner un outil à perte est souvent utilisée par des compagnies de la tech pour devenir hégémonique et ensuite dominer le marché. Il ne faut pas oublier que la déferlante médiatique sur ChatGPT a moussé son utilisation et a constitué un excellent levier de financement.
L’accaparement sans consentement du contenu du web
Pour faire fonctionner ChatGPT, Open AI se base notamment sur de grands modèles de langage (appelés Large Language Mondel ou LLM) qui traitent d’énormes quantités de données. Son processus est simple : faire des suppositions statistiques sur le mot suivant dans une phrase. La chercheuse Emily Bender et al. (2021) nomme ce processus le « perroquet stochastique ». Pour que ces suggestions de mots soient cohérentes, il faut des données massives. C’est la raison pour laquelle ChatGPT, et ses nombreuses versions, ont été entraînés sur des dizaines de trillions de mots et que la compagnie Open AI est à la recherche de plus en plus de données. La question qu’il faut se poser est d’où provienne ces données ? Et comment ont-elles été appropriées ?
Ce que l’on apprend dans notre corpus, c’est que ces données ont été accaparées sur le web sans notre consentement, sans rétribution financière et en contravention aux différentes licences de droits d’auteurs. Ces données ont été collectées à travers la plateforme Common Crawl qui s’alimente depuis 2012 sur le web incluant les contenus de Wikipédia, de LibGen et plusieurs autres bases de données de textes, d’images et de vidéos (Casilli, 2023). Les journaux ayant servi à constituer notre corpus de données ont également servi à entraîner ChatGPT, et ce, sans rétribution financière. Le New York Times ainsi que d’autres institutions médiatiques poursuivent en justice OpenAI pour accaparement de données en violation des droits d’auteurs.
L’opération d’enclosure à laquelle nous assistons avec ChatGPT rappelle la logique des « jardins clos » des médias sociaux corporatifs (van Dijck, 2013). Un écosystème fermé, marchand et sous contrôle de géants numériques comme Microsoft est en train de se reproduire avec des outils comme ChatGPT. C’est justement ce que les nombreuses plaintes contre la start up OpenAI dans tous les secteurs d’activités servent à visibiliser. Ainsi récemment on a pu voir le prix Pulitzer Michael Chabon et d’autres auteurs porter plainte contre les IA de la multinationale Meta (propriétaire de Facebook notamment) et d’OpenAI (Bouhadjera, 2023). Vu également la retentissante grève des scénaristes d’Hollywood, certes pour des raisons salariales, mais aussi par crainte des IA venant marcher sur leurs platebandes (Carrel, 2023) dans la rédaction de scénarios. Autre cas, George R.R. Martin, auteur de la saga Game of Thrones, ainsi que d’autres écrivains ont lancé une poursuite judiciaire contre Open AI, qu’ils accusent d’avoir utilisé leurs œuvres pour créer ChatGPT au mépris de leurs droits d’auteurs. Ils accusent la société d’avoir utilisé leurs livres sans permission pour entraîner son modèle de langage. « Au cœur de ces algorithmes se trouve le vol systématique à grande échelle » (AP, 2023, para. 2), affirment les avocats. Même le Commissariat à la protection de la vie privée du Canada est impliqué puisqu’il a ouvert une enquête à la suite d’une « plainte déposée selon laquelle des renseignements personnels ont été recueillis, utilisés et communiqués sans consentement » (CPVP, 2023, paragr. 3).
Les perroquets stochastiques marginalisent les voix subalternes
Dans un article scientifique, Birhane et Prabhu (2021) nous révèlent que « nourrir les systèmes d’IA de la beauté, de la laideur et de la cruauté du monde, mais s’attendre à ce qu’elles ne reflètent que la beauté est un fantasme » (p. 1542, notre traduction). En utilisant les « représentations » du monde émises par ChatGPT, Bender et al. (2021) soutiennent que nous perpétuons des points de vue dominants, accroissons les déséquilibres de pouvoir et réifions les inégalités (Bender et al., 2021). Ces points de vue hégémoniques qui sont encodés dans les vastes ensembles de données statiques nuisent aux populations marginalisées (Bender et al., 2021). À titre d’exemple, demander à ChatGPT si les Palestinien.ne.s méritent la justice donne une réponse différente de celle que l’on obtient en demandant si les Israélien.ne.s méritent la justice (Bremmer, 2023).
Le recours aux travailleurs et travailleuses du clic dans les Suds et les Nords
L’un des angles morts les moins connus et les plus choquants que nous avons relevés dans notre corpus de données est sans doute celui de l’exploitation de « petites mains » à travers le monde, pour des tâches répétitives et traumatisantes. Il faut en effet « biberonner » l’IA de centaines de milliers d’images, pour les étiqueter, les catégoriser… Pédophilie, mutilations, tortures insoutenables, les pires maux de la terre, tout doit y passer afin que l’IA prenne le soin de ne pas régurgiter ces contenus sensibles. C’est ainsi que des travailleurs et travailleuses sont puisés dans des pays en détresse économique ou des ghettos (Perrigo, 2023). Ce microtravail, que l’on cache comme une maladie honteuse, « n’offre aucun droit, aucune sécurité ou routine et ne rapporte qu’une somme dérisoire – juste suffisante pour garder une personne en vie tout en étant socialement paralysée » (Jones 2021, para. 7, notre traduction). Une certitude… tant que ces tâches seront moins coûteuses à réaliser avec des êtres humains qu’avec des programmes automatisés, elle risque fort de perdurer. À ce sujet, Kate Crawford (2023) nous apprend que c’est à partir d’un laboratoire universitaire en informatique à Stanford dirigée par la professeure FeiFei Li que l’idée de faire étiqueter des images par des personnes est venue. En utilisant des étudiants et étudiantes pour étiqueter des images à un salaire de 10 $ par heure, l’équipe derrière le laboratoire a rapidement constaté le défi titanesque en temps et en ressources qui l’attendait. Alors, elle opta pour le service de Amazon Mechanical Turk. Aucune préoccupation éthique de cette pratique académique ne fut relevée.
Pour décrire ce phénomène, le chercheur Antonio Casilli (2019) parle de « bluff technologique », soit l’invisibilisation des petites mains de l’IAG. D’ailleurs, au début de l’année 2023, un article du Time Magazine a fait beaucoup de bruit en révélant que des « petites mains » de l’IA basée au Kenya permettait à ChatGPT d’être moins toxique (Perrigo, 2023). Pour ce faire, le contenu hautement problématique était manuellement retiré de la plateforme par des « petites mains » africaines avec des salaires de misère. Depuis cet article, les travailleurs essaient de créer le premier syndicat africain des travailleurs du clic pour protéger leurs droits (Perrigo, 2023).
L’impact environnemental majeur de l’utilisation de l’IA générative
L’un des sujets émergents qui proviennent de notre corpus de données est l’empreinte écologique du développement de l’IA. Parmi les impacts néfastes, on compte l’extraction de métaux rares pour fabriquer les (très) coûteuses puces informatiques, la production de déchets, la surconsommation électrique de l’écosystème numérique avec 20 % de l’électricité mondiale absorbée ainsi que la construction de supercentres de données pour entraîner les IA génératives, dont ChatGPT.
L’empreinte carbone et la quantité de ressources qui sont nécessaires pour faire fonctionner les outils de l’IA générative sont faramineuses. Tout d’abord, l’exploitation d’énormes mines à ciel ouvert desquelles on extrait ce qui est nécessaire pour produire nos équipements (téléphones, ordinateurs), mais aussi avec lesquelles on fait fonctionner les grands modèles de langage (LLM) est nécessaire. Comme nous l’apprennent les chercheuses Émilie Bender et al. (2021) le coût environnemental de ChatGPT pénalise notamment les communautés marginalisées qui sont les moins susceptibles de bénéficier des « progrès » technologiques et les plus susceptibles d’être affectées par leurs effets négatifs.
En septembre 2023, on apprenait que Microsoft avait construit un supercentre de données près de la ville de Des Moines en Iowa (O’Brien et Fingerhut, 2023 ; Bach, 2023) afin d’entraîner la plus récente version de leur intelligence artificielle générative, soit ChatGPT-4. Une quantité astronomique d’eau a été pompée dans le but de refroidir le superordinateur utilisé pour apprendre à ses systèmes d’intelligence artificielle à imiter l’écriture humaine. Récemment, nous apprenions que Microsoft envisage l’usage de réacteurs nucléaires de nouvelle génération pour alimenter ses centres de données et son IA (Calma, 2023).
Émilie Bender et al. (2021) nous apprennent qu’un Américain moyen génère environ 5 tonnes de CO2 par an, tandis qu’un modèle Transformer (GPT) avec une architecture neuronale en émet 284 tonnes. Dans une période de sécheresse intense, de feux de forêt et d’autres dérèglements climatiques, il est impératif de prendre la matérialité de ChatGPT au sérieux. À ce titre, l’un des nouveaux casse-têtes des grandes entreprises technologiques est l’activisme contre les centres de données et leurs consommations importantes de ressources (Hogan, 2015 ; Rone, 2023).
Production de connaissance synthétique
Comme nous l’avons lu dans notre corpus de données, l’IA générative créée du contenu que les chercheur.e.s nomment « synthétique ». Le chercheur Graham Meikle (2023) utilise les termes de « contenu synthétique » et « média synthétique » pour décrire les contenus et les médias « artificiels » générés par l’IA générative (texte, image ou vidéo). Dans certains cas, ces contenus artificiels peuvent participer à la création de narratifs alternatifs faux qui visent la désinformation. À titre d’exemple, à la fin septembre 2023, le premier résultat de Google Images pour le terme « tank man » était celui d’un jeune homme chinois prenant un égoportrait devant un tank (Stockel-Walker, 2023). Il n’était donc plus immédiatement associé à ce jeune homme qui, en 1989, a défié un tank chinois sur la place Tiananmen. Cette nouvelle image est le résultat de l’utilisation du logiciel d’IAG Midjourney. Cet exemple met en exergue la facilité avec laquelle il est possible de créer des récits « alternatifs » (faux) avec l’IAG. Quels seront les impacts de la production grandissante de connaissance synthétique sur le web?
Conclusion
Dans cette brève réflexion de recherche, nous avons fait un tour d’horizon qui nous permet de mieux comprendre certains des impacts sociaux, éthiques et environnementaux de ChatGPT. C’est en utilisant la méthode d’analyse d’une situation à partir d’un petit corpus de données que nous avons pu cartographier les différents « tentacules », ou ramifications, de ChatGPT. ChatGPT est bel et bien matériel, ce n’est pas une technologie immatérielle. Elle est l’expression du pouvoir qui résulte de différentes forces sociales, économiques et politiques.
Notre tâche en tant que membres de la communauté étudiante est de mieux saisir les tenants et aboutissants de ces nouveaux outils informatiques dont nous ne parlons pas assez. Nous devons donc être conscient.e. que notre utilisation de l’IAG implique des considérations éthiques qui ont d’énormes coûts économiques, sociaux, humains et environnementaux. Nous espérons qu’avec cette réflexion de recherche, nous serons tous et toutes plus conscients et conscientes de ce qu’implique l’utilisation de ChatGPT.
Bibliographie :
AP.(2023, 20 septembre).Un « vol systématique à grande échelle » : plusieurs auteurs, dont celui de « Game of Thrones », attaquent OpenAI en justice. Le Temps. https://www.letemps.ch/culture/un-vol-systematique-a-grande-echelle-plusieurs-auteurs-dont-celui-de-game-of-thrones-attaquent-openai-en-justice
Bach, D. (2023, 8 septembre). How a small city in Iowa became an epicenter for advancing AI. Microsoft News. https://news.microsoft.com/source/features/ai/west-des-moines-iowa-ai-supercomputer/
Bender, E. et Hanna, A. (2023, 12 août). AI Causes Real Harm. Let’s Focus on That over the End-of-Humanity Hype. Scientific American. https://www.scientificamerican.com/article/we-need-to-focus-on-ais-real-harms-not-imaginaryexistential-risks/
Bender, E., Timnit, G, McMillan-Major, A. et Shmitchell, S. (2021). “Proceedings of the 2021 Acm Conference on Fairness, Accountability, and Transparency.” Essay. In On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 610–23. https://doi.org/10.1145/3442188.3445922. https://s10251.pcdn.co/pdf/2021-bender-parrots.pdf
Birhane, A., et Prabhu, V. U. (2021). IEEE Winter Conference on Applications of Computer Vision (WACV) Waikoloa, HI, USA 2021 Jan. 3 – 2021 Jan. 8. (2021). 2021 ieee winter conference on applications of computer vision (wacv). In Large image datasets: a pyrrhic win for computer vision? (p. 1536–1546). essay, IEEE. https://doi.org/10.1109/WACV48630.2021.00158
Bremmer, I. (2023, 16 octobre). Asking chatgpt about justice for israel/Palestine generates vastly different responses. X. https://x.com/ianbremmer/status/1713985163191837045?lang=en
Bouhadjera, H. (2023, 12 septembre). ChatGPT : c’est au tour d’un Prix Pulitzer de porter plainte contre OpenAI. L’actualité. https://actualitte.com/article/113370/legislation/chatgpt-c-est-au-tour-d-un-prix-pulitzer-de-porter-plainte-contre-openai
Buolamwini, J. (2018, 28 juin). AI, Ain’t I A Woman ? YouTube. https://www.youtube.com/watch?v=QxuyfWoVV98.
Calma, J. (2023, 26 septembre). Microsoft is going nuclear to power its AI ambitions. The Verge. https://www.theverge.com/2023/9/26/23889956/microsoft-next-generation-nuclear-energy-smr-job-hiring
Carrel, O. (2023, 12 juillet) Disney, Netflix… embauchent des spécialistes IA en pleine grève des acteurs ». EcranLarge.com. https://www.ecranlarge.com/films/news/1484696-disney-netflix-ia-greve-acteurs-scenaristes.
Casilli, A. (2023, 7 avril). Intervention au printemps de l’économie. Blogue. https://www.casilli.fr/2023/04/07/video-intervention-au-printemps-de-leconomie-7-avril-2023/
Casilli, A. A. (2019). En attendant les robots : enquête sur le travail du clic. Éditions du Seuil.
Clarke, A. E. (2003). Situational analyses : grounded theory mapping after the postmodern turn. Symbolic Interaction, 26(4), 553–576. https://doi.org/10.1525/si.2003.26.4.553
Clarke, A. E., Friese, C., & Washburn, R. (2018). Situational analysis : grounded theory fter the interpretive turn(Second). SAGE Publications.
Crawford, K. (2022). Contre-Atlas De L’intelligence Artificielle : Les Coûts Politiques, Sociaux Et Environnementaux De L’IA. Zulma Essais. Paris : Éditions Zulma
CPVP. (2023, 25 mai). Le Commissariat enquêtera conjointement sur ChatGPT avec des autorités provinciales de protection de la vie privée. https://www.priv.gc.ca/fr/nouvelles-du-commissariat/nouvelles-et-annonces/2023/an_230525-2/
Hogan, M. (2015). Data flows and water woes: the utah data center. Big Data & Society, 2(2). https://doi.org/10.1177/2053951715592429
Jones, P. (2021, 22 septembre). Refugees help power machine learning advances at Microsoft, Facebook, and Amazon. Rest of World. https://restofworld.org/2021/refugees-machine-learning-big-tech/
McCarthy, J., Minsky, M. L., Rochester, N., & Shannon, C. E. (2006). A proposal for the dartmouth summer research project on artificial intelligence: august 31, 1955. Ai Magazine, 27 (4), 12–14.
Meikle, G. (2023). Deepfakes. Polity Press.
O’Brien, M. et Fingerhut, H. (2023). Artificial intelligence technology behind ChatGPT was built in Iowa — with a lot of water. AP News. https://apnews.com/article/chatgpt-gpt4-iowa-ai-water-consumption-microsoft-f551fde98083d17a7e8d904f8be822c4
O’Neil, L. (2023, 12 août). These Women Tried to Warn Us About AI. Rolling Stone. https://www.rollingstone.com/culture/culture-features/women-warnings-ai-danger-risk-before-chatgpt-1234804367/
Oremus, W. (2023, 5 juin). AI chatbots lose money every time you use them. That is a problem. Washington Post. https://www.washingtonpost.com/technology/2023/06/05/chatgpt-hidden-cost-gpu-compute/
Perrigo, B. (2023, 18 janvier). OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic. Time Magazines. https://time.com/6247678/openai-chatgpt-kenya-workers/
Rone, J. (2023). The shape of the cloud: contesting date centre construction in north holland. New Media & Society, (20230105). https://doi.org/10.1177/14614448221145928
Stockel-walker, C. (2023, 26 septembre). TechScape: AI-made images mean seeing is no longer believing. The Guardian.https://www.theguardian.com/technology/2023/sep/26/techscape-ai-images-elections-integrity-tiananmen-square
Van Dijck, José. (2013). The culture of connectivity : a critical history of social media. Oxford University Press.
Whittaker, M. (2021). The steep cost of capture. Interactions, 28 (6), 50-55. https://doi.org/10.1145/3488666
